Unsupervised Learning auf Nutzungssequenzen von Paid-Content Abonennten
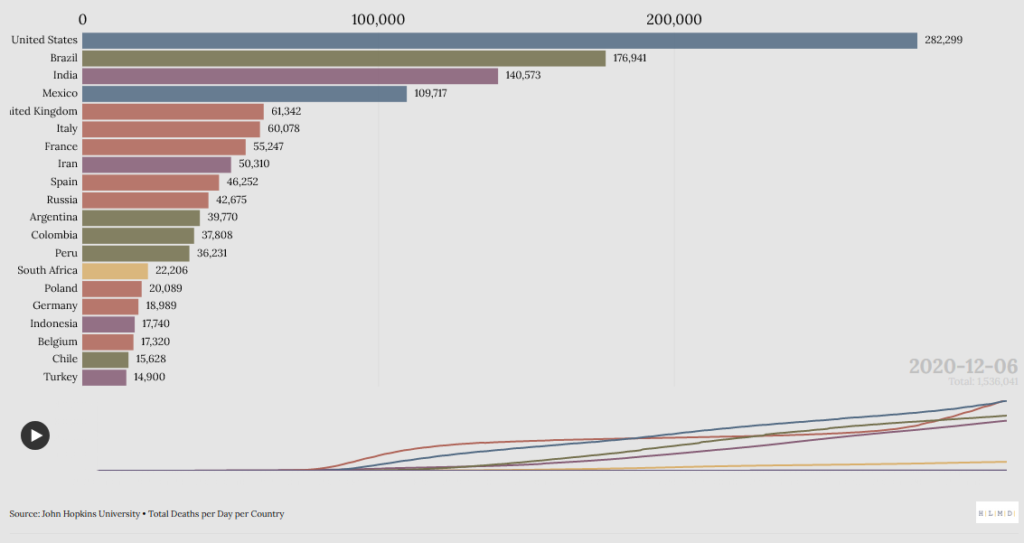
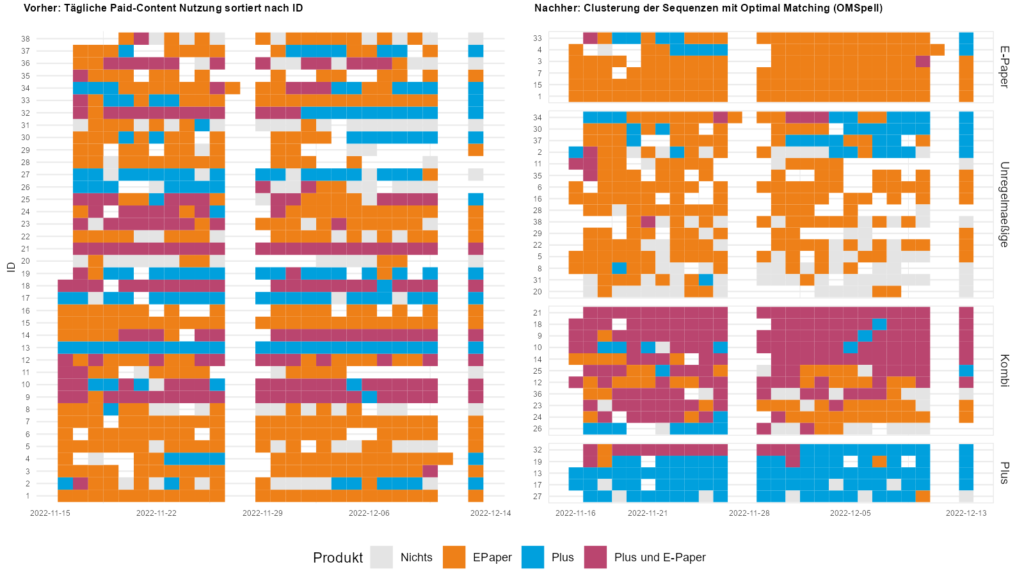
Mit Hilfe eines Unsupervised Learning Verfahrens aus der DNA bzw. Lebenslaufforschung (Optimal Matching) konnten Nutzungssequenzen von Paid-Content Probe-Abonnenten erfolgreich strukturiert und geclustert werden. Die eingesetzte Levenshtein-Distanz Variante (OMspell) brachte selbst bei kleinsten Fallzahlen von n=38 vier recht homogene Gruppen zu Tage. Eingesetzt wurde der Algorithmus bei einer Online-Tagebuchstudie für den Fränkischen Tag, in der täglich die Nutzung von E-Paper und Plus-Artikeln eingetragen wurde. Ein vielversprechender Ansatz der im digitalen…