Category / Data Analysis / Data Visualisation
-
![]()
Unsupervised Learning auf Nutzungssequenzen von Paid-Content Abonennten
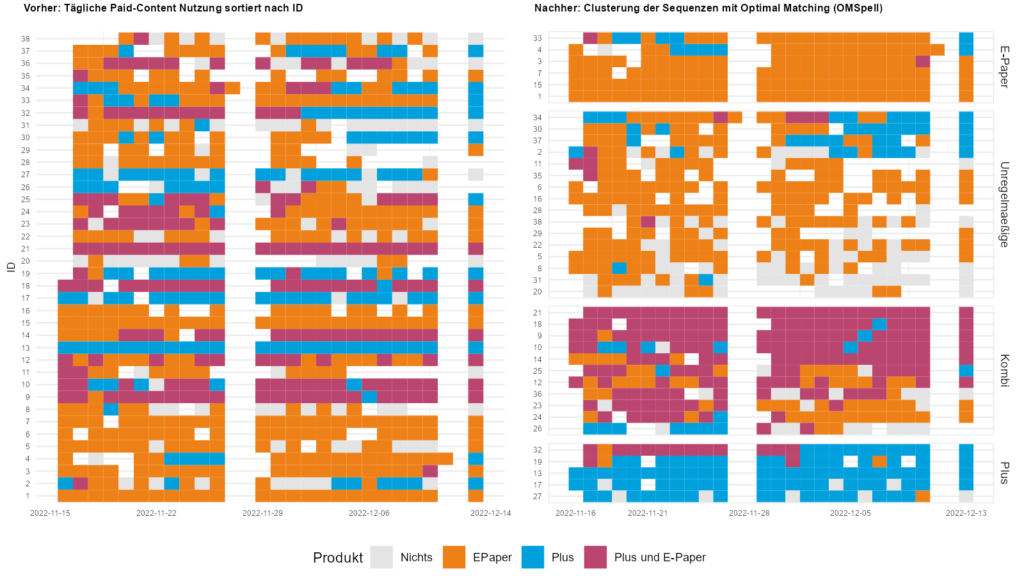
Mit Hilfe eines Unsupervised Learning Verfahrens aus der DNA bzw. Lebenslaufforschung (Optimal Matching) konnten Nutzungssequenzen von Paid-Content Probe-Abonnenten erfolgreich strukturiert und geclustert werden. Die eingesetzte Levenshtein-Distanz Variante (OMspell) brachte selbst bei kleinsten Fallzahlen von n=38 vier recht homogene Gruppen zu Tage. Eingesetzt wurde der Algorithmus bei einer Online-Tagebuchstudie für den Fränkischen Tag, in der…
-
![]()
Zwei Studien im BDZV Jahresreport der AG Digital erschienen
Der aktuelle BDZV-Jahresreport der AG Digital ist heute exklusiv für alle BDZV-Mitglieder erschienen. Mit zwei Studien konnten wir wichtige Facetten zur Digitaliserung beitragen. Großen Dank an die BDZV-Redaktion für das tolle Booklet und die Möglichtkeit die Essays in der Community teilen zu können. Mit der Studie zum Digitalen Journalismus haben wir uns dem spannenden Thema…
-
![]()
How to recode 40.000 brand mentions without training data using a levenshtein distance matrix in R.
If you ever had to deal with open-ended questions in online-interviews you definitely run into the problem of quantifing them. The given responses of the interviewees are often full of typos and mismatches needed to get recoded properly, even worse, most brands have various aliases you have to consider into your analysis. I’ll show you…
-
![]()
Wie Zeitungen Twitter nutzen
Eine quantitative und qualitative Analyse von 18 Zeitungsaccounts und knapp 97.000 Tweets.
-
![]()
Die 4 Typen des deutschen Waldes
Eine Cluster Analyse zur Diversität der Baumartengruppen